오늘은 특정한 기술이나 알리고즘이 아니라 머신 러닝을 사용해서 자연어처리 문제를 푸는 일반적인 과정에 대해서 이야기를 해보려고합니다. 다르게 말하면, 자연어처리 문제를 어떻게 일반적인 머신 러닝 문제 형태로 바꾸느냐에 대한 이야기입니다.
머신 러닝 문제 형태?
머신 러닝 문제 형태라는 것이 무엇일까요? 우리가 흔히 머신 러닝이라고 부르는 것은 실제로는 다양한 알고리즘의 집합니다. 대표적인 머신 러닝 알고리즘들은 아래와 같은 분류에 속합니다 (이 외에 다른 분류도 있습니다).
- Clustering
- Regression
- Classification
Clustering은 비슷한 데이터들끼리 분류하고 모으는 작업입니다. 예를 들어 쇼핑몰의 고객 데이터를 주고, 고객들을 몇가지 부류로 나누는 작업이 있을 수 있습니다. 데이터를 비슷한 부류로 모으다보면 미쳐몰랐던 인사이트를 얻는 경우가 있습니다. 예를 들어 쇼핑몰 고객 데이터에 Clustering을 적용해보았더니 A라는 집단(Cluster)이 생겼는데, 더 자세히 들어여보았더니 특정 지역에 사는 특정 연령대의 사람들은 비슷한 소비를 하더라는 사실을 발견할 수도 있습니다. 이런 분석을 통해서 마케팅이나 판매 전략을 수립할 수 있겠죠.
Regression은 연속된 값을 예측하는 작업입니다. "연속된 값"이라는 표현은 왠지 직관적이지 않으니 예를 하나 들어보겠습니다. 지난 일주일 간의 날씨 데이터를 기반으로 내일 최고 기온을 예측하는 시스템을 만들고 싶다고 가정해보겠습니다. 내일 최고 기온은 21.3도 일 수도 있고, 19.7도 일 수도 있습니다. 이렇게 예측하려는 값이 숫자(정확히는 실수) 형태로 나오는 경우를 Regression 문제라고 합니다.
마지막으로 Classification은 우리의 주된 관심사입니다. Classification에 대해서는 조금 더 자세히 알아보겠습니다.
Classification
Classification은 입력을 Class로 분류한다는 뜻입니다. Class는 미리 정해진 항목라는 뜻입니다. 이 문장은 Classification을 정의하는 중요한 두 가지 정보를 담고 있습니다.
- 미리 정해진: Classification의 대상이 되는 항목은 문제를 풀 때 이미 정해져있습니다. 즉, 문제를 풀고나서 항목을 늘릴 수는 없습니다.
- 항목: Regression과 Classification의 가장 큰 차이는 머신 러닝 알고리즘이 예측하는 값이 연속적이냐 불연속적이냐는 차이입니다. 연속 vs 불연속은 수학적인 표현인데요. 앞의 예처럼 예측하려는 값이 23.4, 23.5 와 같으면 연속적(실수)이고, 예측하려는 값이 맑음, 흐림, 비와 같이 구분된다면 불연속적입니다.
이런 특성 때문에 Classification을 분류 작업이라고도 합니다.
Classification 문제의 예는 어떤 것들이 있을까요?
사진을 보고 강아지인지 고양이인지 맞추는 문제가 있다고 생각해보겠습니다. 이 문제는 예측하려는 값이 고양이와 강아지로 정해져있고, 모든 사진은 고양이와 강아지로 분류되기 때문에 Classification 문제입니다.
또 다른 예로 어떤 제품을 현재 로그인한 고객에게 추천할지 말지 판단하는 머신 러닝 시스템을 생각해보겠습니다. 이 시스템이 예측하는 것은 추천한다, 추천하지 않는다로 정해져있고, 모든 제품에 대해서 이 둘 중 하나로 예측하기 때문에 Classification 문제입니다.
실제로 우리가 아는 머신 러닝(그리고 인공지능) 시스템은 겉으로 보기에 매우 복잡해보이지만 내부적으로는 Classification 문제로 변형해서 푸는 경우가 많습니다.
모든 것은 숫자
한가지 문제는 머신 러닝 알고리즘도 일종의 프로그램이기 떄문에 숫자만을 이해할 뿐 고양이, 강아지, 추천, 비추천이라는 것을 이해하지는 못합니다. 마찬가지로 입력인 고양이 사진, 강아지 사진, 제품의 설명을 이해하지도 못 합니다. 이 떄문에 입력과 출력에 해당하는 값을 숫자로 표현해주는 과정이 필요합니다. 출력은 상대적으로 간단합니다. 고양이는 0, 강아지는 1이라고 약속하고, 나중에 머신 러닝 시스템이 0이라고 예측하면 사용자에게는 고양이라고 보여주고, 1이라고 예측하면 강아지라고 보여주면 됩니다.
하지만 입력은 더 복잡합니다. 어떻게 고양이 사진을 숫자로 표현할까요? 어떻게 나이키의 신상 운동화를 숫자로 표현할까요? 여기에 대해서 이야기하기 전에 자연어처리에 대해서 먼저 이야기를 해보는 것이 좋을 것 같습니다.
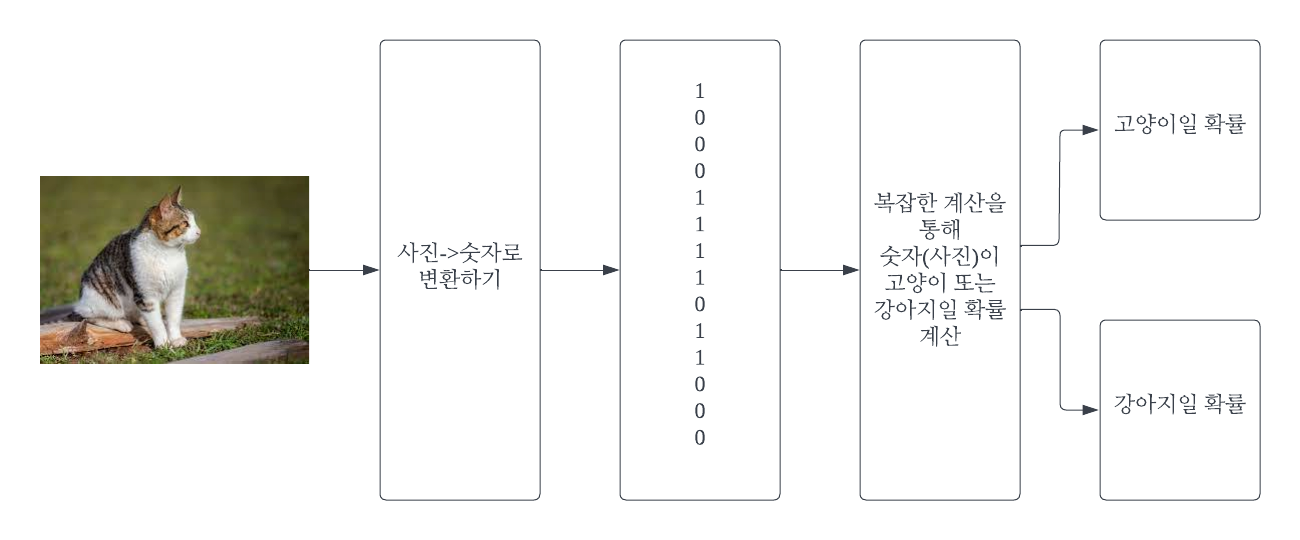
자연어처리
자연어처리를 머신 러닝으로 풀려면 어떻게 해야할까요? 자연어처리 문제를 머신러닝으로 풀기위해서는 문제를 머신 러닝 형태로 바꾸어야합니다.
직관적인 Classification
대표적인 자연처리의 문제 중 하나인 품사 태깅을 예로 들어보겠습니다. 품사 태깅은 단어들의 품사가 무엇인지를 맞추는 문제입니다. 예를 들어,
I have a book.이라는 문장이 있다고 가정하면,
I/대명사 have/일반동사 a/관사 book/명사 ./마침표와 같이 만드는 문제입니다. 다른 예로,
I want to book a ticket.이라는 문제는
I/대명사 want/일반동사 to/전치사 book/일반동사 a/관사 ticket/명사 ./마침표와 같이 될 겁니다. 같은 book이더라도 문맥에 따라 명사가 되기도 하고 동사가 되기도 하는 것을 볼 수 있습니다.
품사 태깅 문제를 어떻게 머신 러닝의 문제 형태로 바꿀 수 있을까요? 먼저 예측해야하는 품사는 그 종류가 미리 정의되어 있습니다 (명사, 일반동사, 관사, 등). 그리고 문장 속의 단어는 이 품사들 중 하나로 분류됩니다. book은 명사일 수도 있고, 동사일 수도 있지만 명사일 때 book과 동사일 때 book은 문맥이 다르기 때문에 다른 단어라고 할 수 있습니다.
(앞에서 이야기하지 않은 머신 러닝 알고리즘의 분류 중 Multi Labelling 이라는 것이 있습니다. 이것은 Classification과 비슷한데 다만 입력이 여러 개의 분류에 속할 수 있습니다. 예를 들어 고양이 사진은 고양이이면서, 동물이고, 포유류일 수 있습니다. Multi Labelling 문제는 Classfication과 많은 부분을 공유합니다. 이번 포스트에서는 Multi Labelling에 대해서는 다루지 않습니다.)
이렇게 놓고 보면 품사 태깅 문제는 전형적인 Classification 문제가 됩니다. 각 단어를 미리 정해진 분류(품사)중에 하나로 분류하는 문제이니까요.
Boundary Detection
이번에는 조금 더 까다로운 예로 명사 추출기를 생각해보겠습니다. 아래와 같은 입력 문장이 있다고 가정해보죠.
서울에는 롯데 타워라는 아주 높은 건물이 있습니다.명사 추출기는 이 문장에서 서울, 롯데 타워, 건물을 추출합니다. (명사 추출기는 검색엔진이나 데이터 분석을 위한 전처리로 많이 사용됩니다.) 이 문제는 전형적인 Classification 문제와는 달라보입니다. 정해진 항목 중 하나로 분류하는 문제가 아니고, 문장에서 특정 부분들을 추출하는 문제니까요. 이런 류의 문제를 Boundary Detection 이라고도 부릅니다. 문제를 아래와 같이 변형해 보겠습니다.
[서울]에는 [롯데 타워]라는 아주 높은 [건물]이 있습니다.입력 문장에서 명사에 해당하는 부분의 경계(Boundary)를 표시하는 것으로 바뀌었습니다.
처음보다는 조금 더 문제가 명확해졌지만 여전히 Classification과는 거리가 멉니다. 한 단계를 더 거쳐보겠습니다. Boundary Detection을 위해서 많이 쓰이는 방법 중 BIO 태깅이라는 것이 있습니다. Beginning, Inside, Outside의 줄임말입니다. Boundary의 시작을 Beginning, Boundary 안을 Inside, Boundary 바깥을 Outside라고 부릅니다. BIO 태깅을 우리 문제에 적용해보면 다음과 같습니다.
서 B
울 I
에 O
는 O
O
롯 B
데 I
I
타 I
워 I
라 O
는 O
O
아 O
주 O
O
높 O
은 O
O
건 B
물 I
이 O
O
있 O
습 O
니 O
다 O
. O서울의 서는 명사의 시작이기 떄문에 B(Beginning)이고, 울은 명사의 일부이기 때문에 I(Inside)입니다. 하지만 에는 명사의 일부가 아니기 때문에 O(Outside)입니다. 우리는 B를 만나면 새로운 명사를 조합하기 시작하고, I가 나오면 그 글자를 이어서 붙이고, O를 만나면 멈추면 됩니다. 이 문제 정의에 따르면 이제 우리는 각 글자가 B, I, O 중 어디에 속하는지 분류하면 됩니다. 즉, 전형적인 Classification 문제가 됐습니다.

조금 더 복잡한 Boundary Detection
이번에는 NER(Named Entity Recognition) 문제를 살펴보겠습니다. NER 문제도 Boundary Detection 문제이지만 이번에는 단순히 Boundary만 찾는 것이 아니라 찾은 Boundary의 종류도 찾아야한다는 점이 다릅니다.
서울에 사는 홍길동은 연세대학교에 다닙니다.라는 문장이 있다고 하면,
<location>서울</location>에 사는 <person>홍길동</person>은 <org>연세대학교</org>에 다닙니다.라고 예측을 해야합니다. 이 문제를 풀기 위해서 두가지 방법을 생각해보겠습니다.
첫번째 방법은 1) Boundary Detection을 먼저하고, 2) 추출된 Boundary를 Location, Person, Org 중 하나로 분류하는 것입니다. 즉, Phase 1에서는 서울, 홍길동, 연세대학교를 추출하고, Phase 2에서 서울, 홍길동, 연세대학교가 각각 어느 분류에 속하는지를 예측합니다. 앞에서 이야기했던 명사 추출기와 품사 태깅의 방법을 차례로 쓴 것입니다.
두번째 방법은 BIO 태깅을 조금 변형하는 것입니다. 단순히 BIO 대신, B-Location, I-Location, B-Person, I-Person, B-ORG, I-ORG, O로 분류를 구체화합니다. 이제 이 새로운 분류를 사용하면 문제를 아래와 같이 정의할 수 있습니다.
서 B-Location
울 I-Location
에 O
O
사 O
는 O
O
홍 B-Person
길 I-Person
동 I-Person
은 O
O
연 B-ORG
세 I-ORG
대 I-ORG
학 I-ORG
교 I-ORG
에 O
O
다 O
닙 O
니 O
다 O
. O첫번째 방법과 다르게 한 번에 Boundary Detection와 종류를 판단할 수 있는 방법입니다.
자연어 처리 문제를 머신 러닝 문제 유형으로 바꾸자
모든 자연어 처리 문제 해결의 시작은 문제를 머신 러닝의 형태로 바꾸는 것에서 시작합니다. 겉보기에는 전혀 달라보이지만 모든 문제가 이런 형태로 변환되고 해결됩니다. 앞에서 든 예 말고 몇가지를 더 들어보겠습니다.
댓글이 긍정적인지 부정적인지는 대표적인 Classification 문제입니다.
이메일 스팸 필터도 메일 본문이 스팸인지 아닌지 분류하는 Classification 문제입니다.
틀린 맞춤법을 찾아주는 기능은 문장에서 맞춤법이 틀린 Boundary를 찾는 Boundary Detection 문제입니다.
기사를 쓰는 인공지능은 기자가 준 몇가지 정보를 입력으로해서 이어질 글자들을 전체 글자(좀 많기는 하지만 여전히 글자는 미리 정해져있습니다) 중 예측하는 문제입니다. 예측한 글자를 이어붙이면 문장이 되고, 기사가 됩니다.
마찬가지로 번역은 입력 문장에 대해서 번역 대상 언어의 글자들 중 예측하는 문제입니다. 한->영 번역이라면 알파벳들을 대상으로 예측하면 됩니다.
심심이로 대변되는 Chatbot은 사용자가 한 말을 기반으로, 가지고 있는 응답 문장 들 중 가장 적합한 문장을 찾는 문제입니다. 아니면 기사 작성이나 번역처럼 글자 또는 단어를 예측해서 문장을 만들 수도 있습니다.
Siri나 Bixby 같은 Voice Assistant는 어떨까요? 예를 들어 사용자가 "내일 서울 날씨 어떄?"라고 했다면 Siri나 Bixby는 아래와 같은 일을 합니다.
- 이 문장을 미리 정해진 의도 (알람 설정, 전화 걸기, 날씨 확인 등) 중 하나로 분류합니다. -> 전형적인 Classification
- 그리고 이 문장 중에서 중요한 정보를 추출합니다. 시간: 내일, 장소: 서울 -> Boundary Detection
다시 모든 것은 숫자
그럼 텍스트로 표현된 언어를 어떻게 숫자로 표현(변환)하느냐는 문제가 남았습니다. 이 부분은 아직도 자연어처리에서 많은 연구가 활발히 이루어지고 있는 부분입니다. 사실 이 언어->숫자 변환 부분을 거치고 나면 나머지 부분은 자연어처리, 음성인식, 이미지인식 등 많은 인공지능 시스템이 기술을 공유합니다. (최근에는 구글에서 발표한 Transformer라는 구조로 대통일(?)이 되가는 분위기입니다.) 텍스트를 숫자로 변환하는 방법은 역사가 매우 깊고 다양하기 때문에 간략히 몇 가지만을 소개하려고 합니다.
Index
가장 간단한 방법은 각 글자에 숫자를 부여하는 것입니다. 예를 들어 가는 1, 나는 2, 다는 3, 라는 4와 같이 숫자를 붙였다면, 나가는 [2, 1]으로 표현할 수 있습니다. 이 방법은 가장 간단하지만 효과적이고, 최근의 딥러닝에서도 많이 쓰이는 방법입니다. 더 응용하자면 꼭 글자에 숫자를 부여할 필요는 없습니다. 입력 단위를 글자가 아닌 글자나, 형태소 (또는 다른 토큰)로 생각하고 숫자를 부여해도 됩니다.
Word Vector
입력 단위에 숫자를 부여하는 방법은 간단하지만 치명적인 문제가 하나있습니다. 예를 들어 왕은 1, 왕자는 2, 왕비는 3, 공주는 4라는 숫자를 부여했다고 가정해보겠습니다. 사람이 보기에는 왕, 왕자, 왕비, 공주는 모종의 관계가 있어보입니다. 하지만 이것들을 숫자로 변환했을 때 1, 2, 3, 4 에서는 이런 관계를 찾아보기가 어렵습니다. Word Vector 기법은 이런 문제를 해결하기 위해서 등장했습니다. 즉, 왕의 숫자는 왕자의 숫자와는 가깝고, 고양이의 숫자와는 멀게 숫자를 정하려고 합니다. Word Vector를 쓰면 입력으로부터 만들어진 숫자들이 의미없는 수자의 나열이 아니라, 단어의 의미(또는 문법)를 가지게 되고, 따라서 전체적인 성능이 좋아진다는 장점이 있습니다.
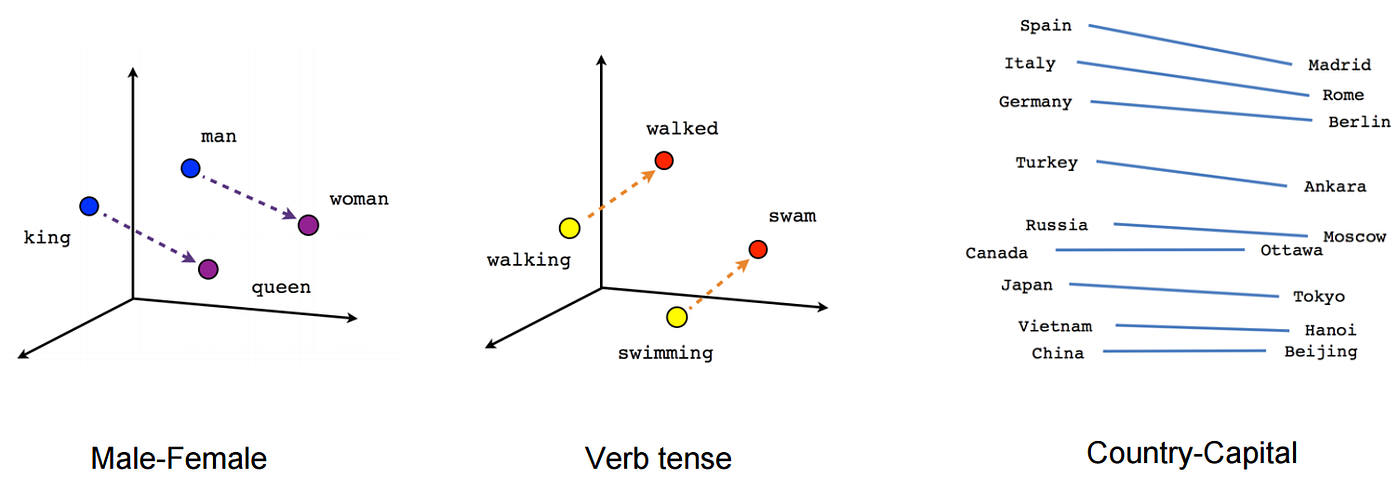
From Creating Word Embeddings: Coding the Word2Vec Algorithm in Python using Deep Learning
BERT (Bidirectional Encoder Representations from Transformers)
Word Vector는 기존의 단순 Index 보다는 훨씬 발전한 방식이지만 여전히 문제점이 있습니다. 바로 각 단어들의 값이 의미를 고려하기는 하지만 이미 값들이 정해져있다는 점입니다. 예를 들어보겠습니다.
1) 나주는 배가 유명합니다.
2) 낚시는 배에서 해야 제 맛이지요.두 문장에서 배는 같은 의미가 아닙니다. 따라서 문맥 안에서 배의 의미를 찾아야합니다. 하지만 Word Vector는 모든 배를 동일한 숫자로 취급합니다. 자연어처리 연구자들은 이를 해결하기 위에서 다양한 방법을 고안해냈는데 이 중에 하나가 BERT입니다. BERT는 배의 숫자를 결정할 때 입력 문장 안에서 단어들의 조합을 고려합니다.
문맥이라고 것은 단어 앞뒤에 어떤 단어가 오느냐도 있지만, 단어가 문장 내에서 어떤 위치를 차지하느냐도 고려합니다.
나주에 들렸을 때 배를 먹으러 과수원에 들린적이 있는데 거기가 매우 아름다웠던 기억이 있습니다.이 문장에서 거기의 의미를 파악할 때 앞 뒤에 어떤 단어들이 왔는지도 중요하지만, 과수원이라는 단어가 앞에 나온 적이 있다는 것도 중요한 정보가 될 수 있습니다.
마치며
오늘 소개해드린 개념들 하나하나는 자연어처리에서 커다란 연구 분야를 이룰 정도로 깊은 주제들입니다. 각 주제별로 자세한 내용은 또다른 포스트들에서 다룰 기회가 있으리라 생각됩니다. 모쪼록 이 글이 머신 러닝으로 어떻게 자연어처리를 다루는지 이해하시는데 조금이나마 도움이 되었으면 합니다.
'Deep Learning' 카테고리의 다른 글
| LLM : LLM을 가능케한 삼박자 (8) | 2023.04.12 |
|---|---|
| LLM : Foundation Model (2) | 2023.04.12 |
| Transformer로 한국어 품사 태거 만들기 (0) | 2021.06.13 |
| Pytorch로 훈련 이어서하기 (checkpoint) (0) | 2021.06.09 |
| Logit, Sigmoid, Softmax (0) | 2021.05.30 |