오늘은 Context Window 크기(Context Length, Context Size라고도 부릅니다)에 대해서 이야기해보려고 합니다. 요즘 정말 많은 LLM들이 있는데요. 정확도, 비용, 속도 등 LLM을 선택하는 많은 기준이 있지만, 중요한 기준 중 하나가 바로 Context Window 크기가 아닐까 합니다. 실제로 새로운 LLM이 발표될 때마다 Context Window 크기 자랑이 빠지지 않는 것을 볼 수 있습니다. Google은 Gemini가 Context Window를 1M tokens까지 지원한다고 발표하기도 했고요.
Context Window 크기가 무엇이길래, 그리고 얼마나 중요하고 어려운 기술이길래 새로운 LLM을 발표할 때마다 중요하게 다루는 걸까요?
Context Window가 뭐지?
Context Window는 간단히 말하면 LLM의 넣을 수 있는 최대 입력 크기입니다. ChatGPT를 쓴다고 하면 ChatGPT에게 물어보는 질문이나 시키려는 지시의 길이입니다.
LLM은 데이터를 글자 단위로 처리하지 않고 Token 단위로 처리하기 때문에 Context Window의 크기는 몇 Token이다라고 말합니다. Token에 대해서 자세히 다루려면 별도 포스트가 필요할 정도로 복잡한 주제라서 이 글에서는 다루지 않으려고 합니다. 언어에 따라 다르지만 영어 기준으로 대략 1 Token = 4 글자라고 보면 얼추 비슷합니다.
대표적인 모델들의 Context Window 크기는 아래와 같습니다.
| Model | Context Window 크기 |
|---|---|
| GPT 3.5 | 4K |
| GPT 4 | 8K |
| GPT 4-32K | 32K |
| LLaMA 2 | 4K |
| Gemini | 32K |
| Gemini | 1M |
간단히 말하면 LLM이 지원하는 Context Window 크기가 클수록 더 많은 데이터를 입력으로 넣을 수 있다고 볼 수 있습니다.
Context Window가 크면 뭐가 좋지?
예를 들어 문서 요약기를 LLM을 이용해서 만들고 있다고 가정해 보겠습니다. 아마 아래와 같은 프롬프트를 사용할 겁니다.
너는 주어진 문서를 짧은 형태로 요약해주는 요약기야.
요약할 때는 원문에 있는 문서만 사용해야하고, 원문의 언어를 그대로 사용해야해.
아래 원문의 내용을 요약해줘
(원문)그리고 (원문)이라고 된 부분에 요약하고자 하는 문서를 넣고요. 얼마나 긴 문서를 넣을 수 있느냐는 LLM이 지원하는 Context Window 크기에 달렸습니다. 영어 기준으로 단편 소설이 100K Token 정도라고 합니다. 해리포터와 마법사의 돌이 대략 이 정도 분량이라고 합니다. 반지의 제왕은 약 750K라고 하고요.
단순한 텍스트(Plain Text)만 기준으로 삼으면 이렇지만 HTML이나 PDF처럼 Text 외에 Tag 같은 추가 정보가 붙은 문서를 입력한다고 가정해 보면 Context Window 크기는 더 커집니다.
심지어 요즘 급속도로 발전하고 있는 Multi-Modal LLM 까지 확장해 보면 더욱 그렇습니다. 최신 LLM들은 Text 외에도 이미지, 비디오, 음성 등도 입력으로 받을 수 있는데요. 이런 모든 입력 수단이 Context Window 크기를 차지합니다. 예를 들어 Gemini 1.5의 1M Context Window를 사용하면 비디오 1시간, 오디오 11시간을 입력으로 넣을 수 있다고 홍보하고 있습니다.
많은 사람들이 LLM을 활용하면서 LLM에 입력으로 넣으려는 데이터가 점점 복잡해지고 길어지는 것은 당연한 일이라고 생각합니다. 따라서 더 큰 Context Window를 가진 LLM이 매력적이 되는 것도 당연한 일이고요.
Context Window를 키우기 어려운 이유
앞에 살펴본 것처럼 LLM을 쓰는 입장에서는 Context Window가 크면 좋습니다. 그런데 LLM들이 Context Window 크기를 늘리는데 어려움을 겪는 이유는 무엇일까요? 새 LLM을 발표할 때 늘어난 Context Window 크기를 자랑하는 것을 보면 Context Window를 늘리는 것이 쉬운 일이 아닌 것은 분명해 보입니다.
지금부터는 Transformer 내부 이야기로 들어가기 때문에 Transformer에 대한 기술적인 이해가 필요합니다. Transformer가 생소하신 분들은 제 블로그의 글이나 인터넷상의 Transformer 소개글을 먼저 읽어보시기를 추천드립니다.
Context Window 크기는 모델 파라미터와 관계없다
Context Window 크기라는 개념을 처음 접하면 드는 생각 중 하나가 Context Window 크기를 제약하는 요인이 무엇인가라는 질문입니다. Transformer 모델의 크기를 정하는 많은 파라미터들이 있습니다. embedding dimension, attention header 개수, encoder/decoder block 개수 등이 그렇습니다. 이 값들은 모델을 정의할 때 정하는 값이기 때문에 모델 훈련을 마치고 나면 바꿀 수 없는 값입니다.
Context Window 크기는 이떤 파라미터 값에 의해 정해질까요? 정답은 그런 파라미터는 없다입니다. Transformer에는 구조적으로 Context Window 크기를 제한하는 부분이 없습니다. 입력 길이가 길어지면 그만큼 입력 Vector가 길어질 뿐 구조적으로 긴 입력을 막는 부분은 없습니다.
그럼 LLM들이 각자 다른 Context Window 크기를 지원한다는 것은 무슨 의미일까요? 바로 성능(품질)에 대한 이야기입니다. 예를 들어 GPT 3.5가 4K Context Window를 지원한다는 것은 GPT 3.5는 4K Token 입력까지만 성능을 보장할 수 있다는 의미입니다. Gemini가 1M Context Window를 지원한다는 이야기는 1M Tokens 입력까지도 성능을 보장할 수 있다는 이야기이고요.
다르게 말하면 4K Context Window를 지원한다는 LLM에 8K 입력을 넣더라도 LLM은 결과를 생성할 수 있습니다. 대신 생성되는 결과의 품질은 좋지 않습니다. 그런데 실제로 GPT API나 Gemini API를 써보면 각 LLM이 지정한 값 이상을 넣을 수 없거나 넣으면 일부가 잘리는 문제가 있습니다. 이것은 어떻게 된 것일까요? 이 제약은 LLM 자체가 아닌 API의 설정에 달려있습니다. API를 제공하는 쪽에서 LLM이 성능을 보장할 수 있는 범위로 입력을 제한하고 있는 것입니다.
훈련 데이터 문제
그렇다면 LLM 별로 자신있게 품질을 보장하는 Context Window 크기가 제한되는 이유는 무엇일까요?
첫 번째는 훈련 데이터입니다. LLM의 성능에 가장 큰 영향을 주는 것 중 하나는 바로 훈련 데이터입니다. 얼마나 양질의 다양한 데이터를 모델에게 보여주느냐가 모델의 품질을 좌우합니다. 그렇기 때문에 좋은 LLM을 만들기 위해서는 많은 양의 데이터를 확보해야 하고, 모은 데이터를 고품질로 만들기 위한 작업이 필요합니다.
평생 10쪽 짜리 소설만 읽은 사람이 있다고 가정해 보겠습니다. 엄청난 다독가인 이 사람은 수십만, 수백만 권의 짧은 소설을 완독 했습니다. 그 덕에 짧은 소설을 쓰는 능력이 세계적인 수준에 이릅니다. 하지만 이 사람에게 10여 권이 넘는 대하소설을 쓰라고 하면 어떻게 될까요? 아마 어느 정도 품질의 글은 쓰겠지만, 우리가 기대하는 품질의 대하소설이 나오기는 어려울 겁니다.
LLM도 마찬가지입니다. LLM이 큰 Context Window를 지원하기 위해서도 이에 걸맞는 훈련 데이터가 필요합니다. 큰 Context Window를 통해 들어오는 긴 입력을 문제없이 이해하려면, 훈련할 때 그만큼 긴 입력을 학습해야 합니다. 하지만 문제는 엄청나게 긴 텍스트 데이터를 대량으로 구하기가 쉽지 않다는 점입니다. 짧은 텍스트 데이터를 무작위로 이어 붙이면 길이는 충족되겠지만, 그런 데이터가 양질의 데이터라고 부르기는 어렵습니다.
속도 문제
입력이 길어지면 그만큼 처리 시간이 길어지는 것은 당연한 일입니다. 이 문제는 훈련과 해석시에 모두 적용됩니다. 특히 Transformer는 내부적으로 Attention 구조를 사용하기 때문에 입력이 제곱으로 복잡도가 올라갑니다. 단순 계산으로 입력 길이가 두 배가 되면 처리 시간은 4배가 됩니다.
6개월 동안 훈련시키면 됐다면 1년 동안 훈련을 시켜야합니다. 그만큼 시간과 돈이 들어갑니다.
해석 때는 3초 걸릴 일이 6초가 걸립니다. 그만큼 단일 시간에 서비스할 수 있는 사용자가 줄어들고 수익성이 나빠집니다. 그렇기 때문에 API 비용을 올려야 합니다.
Context Window 크기 때문이 아니더라도 LLM의 속도를 빠르게 하기 위한 많은 연구가 있어왔고 많은 성과를 내고 있습니다. FlashAttention, MQA, GQA 등이 대표적인 예입니다. 이런 기술들을 도입한 LLM들의 설명을 보면 해석(Inference) 속도가 빨라졌고, 따라서 더 큰 Context Window를 지원할 수 있게 됐다는 설명을 볼 수 있는 이유가 이 때문입니다.
Postional Encoding
또 다른 기술적인 문제는 Positional Encoding이라는 Transformer의 구조입니다.
최초 Transformer 구조를 보면
- 입력을 Token으로 바꾸고
- Token을 Embedding으로 바꾸고
- 각 Token의 Positional Encoding을 2에 더하고
- 3의 값을 Self Attention으로 보내는
단계를 거칩니다. 이 중 2단계의 Embedding은 각 Token의 의미를 Vector 형태로 표현한 것이고, 3단계의 Postional Encoding은 입력 내에서 각 Token의 위치를 Vector로 표현한 것입니다.
문제는 초기 Transformer에 쓰인 Positional Encoding 기법이 Token의 절대적 위치를 표현한다는 점입니다. Positional Encoding을 구현하는 방법은 여러 가지가 있지만 우리 논의에서 중요한 것은 Token의 위치에 따른 Vector 값이 정해진다는 점입니다. 다르게 말하면 첫 번째 Token의 값은 AAAAA이고, 두 번째 Token의 값은 BBBBB입니다. 그리고 4,096번째 Token의 값은 ZZZZZ입니다. 모델을 훈련할 때 보여준 가장 긴 입력이 4,096였다면 이 모델은 ZZZZZ라는 Positional Encoding 값까지만 본 셈이 됩니다.
이렇게 훈련된 모델에 8,192 길이의 Token을 입력으로 넣었다고 가정해 보겠습니다. 앞에서 사용한 Positional Encoding은 Token의 위치를 가지고 Vector 값을 계산하기 때문에 8,192 번째 Token의 값도 문제없이 생성합니다. 이 값이 ZZZZZZAAAA라고 해보죠. 문제는 모델이 이 값을 본 적이 없다는 점입니다. 그렇기 때문에 입력을 이해하는 품질이 떨어지고, 따라서 생성하는 결과의 품질 또한 떨어집니다.
이 문제를 극복하기 위해 여러 가지 방법이 시도됐습니다. 그중 가장 효과적이라고 알려진 두 가지 방법을 간단히 소개해보겠습니다.
ALiBi
첫 번째는 Positional Encoding을 할 때 Token의 절대적인 위치(첫번째, 두번째, ...)가 아닌 각 Token 간의 상대적인 위치를 사용하는 방식입니다. ALiBi(Attention with Linear Biases)라는 방식이 대표적입니다. ALiBi는 Potional Encoding(Token의 절대적인 위치)을 Token Embedding에 더하는 대신 Attention을 계산할 때 Token의 위치를 고려합니다.
"어제 친구랑 놀았는데 너무 재미있었어."라는 문장과 "그런데 있잖아 어제 친구랑 놀았는데 진짜 재밌었어."라는 문장을 예로 들어보겠습니다. "친구랑"이라는 단어(논의를 간단히 하기 위해서 Token 대신 단어를 사용하겠습니다. 정확히는 단어도 아니고 어절이지만...)와 "놀았는데"라는 단어가 얼마나 관련(Attention)이 있는지 계산을 한다고 가정해 보죠. 첫 번째 문장에서는 "친구랑"이 두 번째 단어이고, "놀았는데"는 세번째 단어입니다. 두번째 문장에서는 "친구랑"은 네 번째 단어이고, "놀았는데"는 다섯 번째 단어입니다. 같은 단어이지만 절대적 위치를 사용하는 Positional Encoding 방식의 값은 달라집니다. 그런데 두 단어 사이의 관련성(Attention)을 계산하는데 절대적인 위치가 정말 중요할까요? 오히려 그것보다 "놀았는데"가 "친구랑" 바로 다음에 온다는 정보면 되지 않을까요? 다르게 말하면 두 단어의 거리가 1이라는 사실이면 되지 않을까요?
ALiBi는 이 아이디어에 착안해서 절대적인 위치를 사용하는 대신 Attention을 계산할 때 상대적인 거리를 더하는 형태로 위치 정보를 활용합니다. 이 방식은 입력 길이에 관계없이 Token 간의 거리만 따지기 때문에 훈련 시에 보여준 길이보다 긴 입력이 들어와도 문제없이 처리할 수 있게 됩니다. "어제 친구랑 놀았는데 너무 재미있었어."라는 문장과 "그런데 있잖아 어제 친구랑 놀았는데 진짜 재밌었어."이 길이는 다르지만 "친구랑"과 "놀았는데" 사이 거리는 여전히 1인 것과 같습니다.
실제로 ALiBi로 훈련된 LLM은 훈련 때 사용한 가장 긴 데이터보다 훨씬 긴 데이터를 해석 시에 넣어도 성능 저하가 별로 없는 것으로 알려져 있습니다.
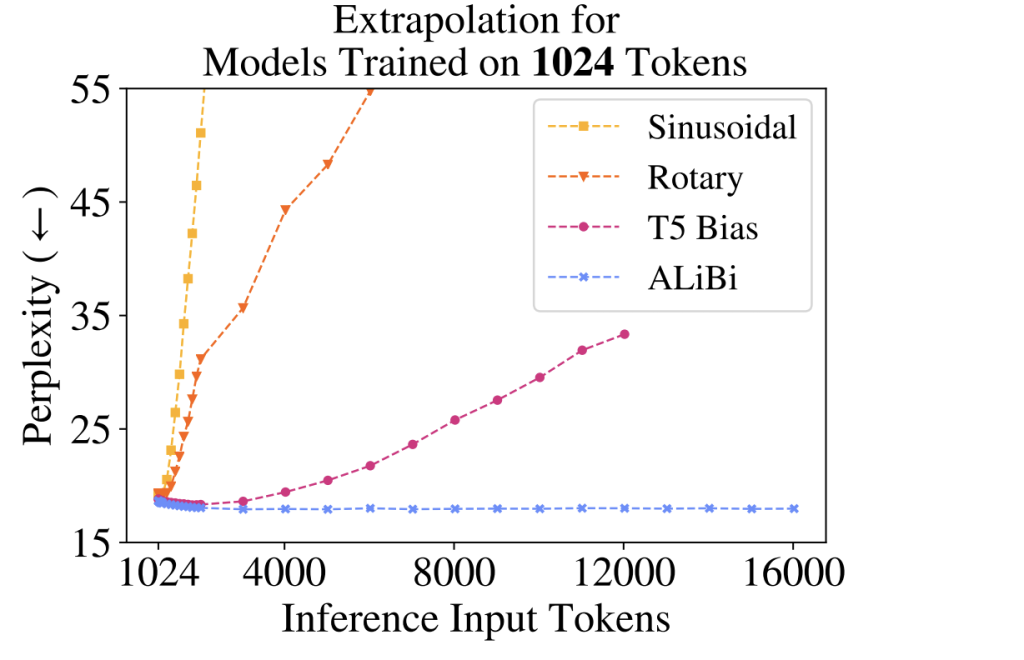
하지만 ALiBi에는 문제가 한 가지 있습니다. 바로 LLM을 훈련시키는 단계에서 사용해야 한다는 점입니다. 즉 LLM을 처음부터 훈련시킬 때 쓸 수 있는 방법입니다. 하지만 대부분의 사람들은 공개된 LLM을 그대로 사용하거나 Fine Tuning 한 후에 사용합니다. 이때 사용할 수 있는 방법이 Positional Interpolation입니다.
Positional Interpolation
Positional Interpolation은 훈련된 LLM은 건드리지 않고 Potional Encoding 영역을 좀 더 쪼개 쓰는 방식입니다. 예를 들어 원래 모델의 Context Window가 4였다고 해보겠습니다. 그럼 Token의 위치는 [0, 1, 2, 3] 중에 하나가 될 겁니다. 그런데 우리는 이 모델을 그대로 쓰면서 Context Window를 8로 늘리고 싶습니다. Positional Interpolation을 사용하면 가능한 Token의 위치가 [0, 0.5, 1, 1.5, 2, 2.5, 3, 3.5]가 됩니다. Index 1번 Token은 실제로 0.5번째 Token이 되는 식입니다. Postional Encoding을 계산하는 함수는 실수를 입력으로 받을 수 있기 때문에 0.5, 1.5 같은 위치에 대해서도 문제없이 계산할 수 있습니다.

Positional Interpolation 방식을 쓰면 LLM을 바닥부터 다시 훈련시키지 않고도 적은 성능 저하만으로 더 큰 Context Window를 사용할 수 있습니다. 하지만 ALiBi를 써서 처음부터 훈련시키는 것보다는 성능이 떨어지는 것은 피할 수 없는 일이기는 합니다.
Context Window 크기 증가 경쟁
LLM 업체들이 Context Window 크기를 경쟁적으로 늘리는 것에는 여러 이유가 있습니다.
LLM에게 더 많은 데이터를 보여줄 수 있기 때문에 성능을 개선하는데도 도움이 됩니다. LLM을 진지하고 심각하게 사용하는 경우가 늘어나면서 더 큰 Context Window를 원하는 고객의 니즈도 늘어나고 있습니다. 갈수록 치열해지는 Multi-Modal LLM을 생각하면 이런 필요성을 더욱 커지고 있습니다. 마케팅적으로 LLM의 우수성을 알리기도 좋고요.
하지만 더 큰 Context Window를 제공하기 위해서는 그만큼 비용이 따릅니다. 모델을 만들 때도 그렇고 서비스할 때도 그렇습니다. LLM 업체들이 Context Window 크기에 따라 여러 모델을 여러 가격으로 제공하는 이유가 그 때문입니다. 사용자 입장에서는 4K Context Window면 충분한데 128K Context Window용으로 비싼 API를 사용할 이유는 없으니까요.
오늘 살펴본 것처럼 Context Window 크기라는 숫자 뒤에는 여러 가지 재미있고도 복잡한 기술적이 내용들이 담겨있습니다. 이번 포스트가 이런 내용을 이해하는데 조금이나마 도움이 되었으면 하는 바람입니다.
'Deep Learning' 카테고리의 다른 글
| LLM : On-Device LLM (2) | 2024.08.29 |
|---|---|
| LLM : Token (2) | 2024.06.10 |
| LLM : RAG (3) | 2024.04.28 |
| LLM : Fine Tuning & LoRA (3) | 2023.11.12 |
| Cross Entropy 이야기 (0) | 2023.05.21 |