스포일러! 2편은 다른 편에 비해 다소 기술적인 내용이 많습니다.
Large Language Model
Language Model이 커지면 뭘까요? 바로 Large Language Model입니다. 하지만 무작정 크게 만들 수는 없습니다. 아래 세가지 문제 때문입니다.
- 훈련 데이터 : 엄청 많은 데이터가 필요합니다.
- 알고리즘 : 기존보다 엄청 강력한 알고리즘이 필요합니다.
- 컴퓨팅 파워 : 엄청 많은 그리고 좋은 컴퓨터가 필요합니다.
우리가 LLM을 만들고 있다는 것은 이 문제들이 어느 정도 해결이 됐다는 뜻이겠지요?
(이 세가지는 전통적인 Machine Learning에서 Deep Learning으로 넘어갈 수 있었던 요인이기도 합니다. 앞으로 더 강력한 Machine Learning 기법이 나오더라도 반복될것이고요.)
훈련 데이터
모든 Machine Learning은 훈련 데이터가 필요합니다. 강력한 모델을 만들고 싶다면 그만큼 많은 데이터가 필요합니다. Machine Learning 모델을 만들 때 가장 큰 어려움이기도 하죠. 데이터를 모으는 것도 어렵고, 이 데이터에 정답(긍정/부정, 사람이름 위치)을 태깅하는 것도 어렵습니다.
하지만! LM은 이 두가지 문제에서 비교적 자유롭습니다.
Self-supervised Learning
먼저 정답을 만드는 태깅 작업에 대해서 이야기해보겠습니다. 사람이 해야하기 때문에 시간도 돈도 많이 드는 일입니다. 시간과 돈이 많이 든다 -> 양을 많이 만들기 힘들다라는 뜻이기도 합니다.
하지만! LM 훈련을 위해서는 사람이 개입할 필요가 없습니다. "나는 어제 학교에 갔습니다."라는 문장이 있다고 해보겠습니다.
- 나는 -> 어제
- 나는 어제 -> 학교에
- 나는 어제 학교에 -> 갔습니다.
LM에게 위의 세가지를 보여주면 됩니다. 그리고 이 세가지는 "나는 어제 학교에 갔습니다."라는 문장을 가지고 자동으로 만들 수 있습니다. 사람이 직접 만들 필요가 없습니다.
즉, 텍스트만 있다면 LM을 위한 훈련데이터는 사람의 손을 타지 않고 자동으로 만들 수 있습니다.
정답 데이터가 없이 모델을 훈련시키는 방법을 Unsupervised Learning이라고 부릅니다. 그런데 요즘은 Self-supervised Learning이라는 표현도 씁니다. Unsupervised Learning은 정말 답이 없는 경우이지만 Self-supervised Learning은 데이터로부터 답을 만들 수 있는 경우입니다. 앞에서 설명한 훈련 데이터 특성 때문에 LM 훈련은 보통 Self-supervised Learning이라고 부릅니다.
Web Scale Data
데이터의 양은 어떨까요? 예전에 구할 수 있는 텍스트 데이터는 공개된 신문기사, 저작권을 산 책, 국립국어원에서 공공사업으로 만든 데이터, 개인이 크롤링한 데이터 정도였습니다. 기껏해야 수십 MB에서 수백 MB였죠. 수 GB인 위키피디아 덤프 파일은 어마어마한 양이었습니다.
그런데 Web Scale Data 들이 등장하면서 판이 바뀌었습니다. Web의 근간은 텍스트 데이터이고, Web에 존재하는 데이터의 양은 무시무시할 정도입니다. 그 거대한 위키피디아 조차 Web의 아주 일부일 뿐이니까요. 그리고 이 Web을 크롤링해서 모으는 사람들이 있습니다. 대표적인 프로젝트가 Common Crawl이라고 불리는 프로젝트입니다. 이 Web Scale Data들은 수 TB ~ 수십 TB입니다. Web이 커질수록 이 데이터도 덩달아 커지고 있죠. 무엇보다 최고인 점은 공개(무료) 데이터라는 점입니다.
이 뿐 아니라 데이터를 많이 보유한 웹 사이트들도 자신들의 데이터(물론 공개할 수 있는 범위에서)를 공개하고 있습니다. 크롤링 데이터보다 양은 적지만 아무래도 관리된 데이터이기 때문에 품질면에서는 우수합니다.
두가지가 합쳐지면
LM 훈련이 가지는 Self-supervised Learning이라는 특성과 Web Scale Data가 만나면서 엄청난 시너지가 생겼습니다. LM을 훈련시키기 위한 엄청난 양의 데이터를 자동으로 확보하게 된 것입니다.
알고리즘
아무리 데이터가 많더라도 이 데이터를 소화할 좋은 알고리즘이 있어야합니다. 이 때 등장하는 것이 바로 그 이름도 유명한 Transformer입니다.
Transformer는 2017년에 구글이 발표한 Deep Learning 알고리즘입니다. Transformer 아키텍쳐라고도 부르고 구조라고 부르는데 뭐라고 부르든 크게 상관은 없습니다. 이 글에서도 섞어서 쓸 예정입니다.
Transformer가 도대체 무엇이길래 이 엄청난 일들을 해내고 있을까요? 사실 Transformer를 제대로 이해하기 위해서는 많은 배경 지식과 Deep Learning 계의 지난 날들을 알아야합니다. 필요한 부분만 짚어 보겠습니다.
Sequence to Sequence
Transformer를 이해하기 위해 먼저 알아야할 필수적인 개념으로 Sequence to Sequence (seq-to-seq)이라는 것이 있습니다.
먼저 Sequence가 무엇일까요? Sequence는 무엇인가가 줄줄이 서있는 것을 뜻합니다.
- 1, 5, 3, 2, 1 -> 숫자 Sequence
- 개미, 개구리, 강아지, 말 -> 동물 Sequence
- 나는, 어제, 학교에, 갔다. -> 단어 Sequence
이 중 우리의 관심사는 마지막 단어 Sequence입니다. 그리고 우리는 보통 단어 Sequence를 문장이라고 부르죠. 좀 더 확장해서는 텍스트라고 부를 수도 있습니다. 앞으로 Sequence라고 이야기할 때는 문장(또는 텍스트)라고 생각해 주시면 됩니다.
그렇다면 Sequence to Sequence는 문장 to 문장이라는 뜻입니다. 한 문장을 다른 문장으로 변환하는 태스크라는 뜻입니다.
가장 대표적인 Sequence to Sequence 태스크는 번역입니다.
- "나는 어제 학교에 갔다." -> "I went to the school yesterday."
한국어 문장을 영어 문장으로 변환했습니다.
요약도 Sequence to Sequence 태스크로 볼 수 있습니다. 긴 텍스트를 짧은 텍스트로 변환하기 때문입니다.
생각을 조금 더 확장해보면 Sequence to Sequence는 정말 무궁무진합니다. 이게 Sequnce to Sequence야 싶은 것도 다 Sequence to Sequence의 범주에 들어갑니다.
- 리뷰가 긍정인지 부정인지 판단하는 태스크를 생각해보겠습니다. 가장 흔한 접근은 긍정 또는 부정 중 하나로 분류하는 Classification 방법입니다. 하지만 리뷰를 입력 텍스트로 생각하고, "긍정" 또는 "부정"이라는 텍스트로 변환하게 한다면 Sequence to Sequence 태스크가 됩니다.
- "제 이름은 홍길동입니다." -> "제 이름은 홍길동입니다." 과 같이 문장에서 이름 부분을 찾는 태스크를 생각해보죠. 가장 흔한 접근은 BIO 태그를 써서 Classification으로 푸는 문제입니다. 하지만 "제 이름은 홍길동입니다."를 입력으로 생각하고, "제 이름은 홍길동입니다."라는 문장을 생성한다고 생각하면 이 역시 Sequence to Sequence 문제가 됩니다.
이처럼 Sequence to Sequence는 거의 모든 자연어처리 태스크에 적용할 수 있는 방법론입니다.
그럼 Sequence to Sequence를 어떻게 구현할 수 있을까요? 한 단계 더 들어가보겠습니다.
"나는 어제 학교에 갔다." 라는 문장을 어떻게 "I went to the school yesterday."로 번역하시나요? 차근히 머리속에서 일어나는 일을 되짚어 봅시다.
정답은 "모른다"입니다. 우리는 우리 뇌가 어떻게 번역을 하는지 모릅니다. 하지만 그럴듯한 한가지 가설이 있습니다. Inter-lingua(인터링구아)라는 설인데요. 한국어, 영어는 다른 언어지만 의미를 표현하는 어떤 중간 언어가 있을 것이고, 그 언어가 Inter-lingua라는 주장입니다.
- "나는 어제 학교에 갔다." -> "I went to the school yesterday."
이렇게 번역하는 것이 아니라 실제로는,
- "나는 어제 학교에 갔다." 를 Inter-lingua로 변환
- Inter-lingua를 "I went to the school yesterday."로 변환
- "나는 어제 학교에 갔다." -> 변환 -> (Inter-lingua로 표현된 의미) -> 변환 -> "I went to the school yesterday."
우리가 한국어 단어를 영어 단어로 하나하나 변환하는 것이 아니라 문장의 의미를 이해하고, 그 의미에 맞는 영어 문장을 만든다는 것을 생각하면 말이 되는 가설같기도 합니다.
앞에서는 변환이라는 표현을 썼는데요. 조금 더 따져보면 1단계와 2단계에서 변환은 살짝 다릅니다. 다시 써보면,
- "나는 어제 학교에 갔다." 를 Inter-lingua로 부호화
- Inter-lingua를 "I went to the school yesterday."로 복원(생성)
- "나는 어제 학교에 갔다." -> 부호화 -> (Inter-lingua로 표현된 의미) -> 복원(생성) -> "I went to the school yesterday."
"나는 어제 학교에 갔다."와 "I went to the school yesterday."는 한국어와 영어이기는 하지만 둘 다 사람이 사용하는 언어라는 공통점이 있습니다.
하지만 (Inter-lingua로 표현된 의미)는 사람이 알아듣는 언어는 아닐 것입니다. 애초에 우리가 만들어낸 가상의 개념이기도 하고요.
개념적으로 표현해보자면 Inter-lingua아와 사람의 언어(자연어)는 다른 층에 속하는 셈입니다.

부호화, 복원, 생성이라는 용어가 일상적인 표현은 아니기 때문에 용어에 대해서 이야기를 하고 넘어가겠습니다.
- 부호화: 다른 데이터 형태로 변환하는 것을 의미합니다. 예를 들어 동영상 파일을 생각해보겠습니다. 동영상 파일은 데이터 덩어리일 뿐 우리가 눈으로 보는 실제 빛은 아닙니다. 우리는 빛으로 표현된 정보를 우리가 정의한 다른 형태인 동영상 파일로 변환하고 저장합니다. 다르게 말하면 빛으로 표현된 데이터를 동영상 파일 형태로 부호화합니다. 음악 파일도 그렇고, 이미지 파일도 그렇습니다.
또다른 예는 파일 압축입니다. 우리가 파일을 압축하고 나면 압축된 파일은 원래 파일에서 오기는 했지만 내용물은 원래 파일과 다릅니다. 우리는 원본 파일을 압축 파일로 부호화합니다. - 복원(생성): 친구에게 동영상 파일을 받았다고 해봅시다. 이 동영상 파일을 보려면 어떻게 해야하나요. 이 동영상 파일을 그냥 볼 수는 없고 동영상 재생기라는 별도의 프로그램이 필요합니다. 이미지 파일을 보려면 이미지 뷰어가 필요하고, 음악 파일을 들으려면 음악 파일 재생기가 필요합니다. 부호화된 데이터(동영상 파일, 음악 파일, 이미지 파일)를 우리가 이해할 수 있는 형태로 다시 복원시켜주어야하기 때문입니다.
압축 파일의 경우는 압축을 해제하는 것이 복원에 해당합니다.
복원은 다르게 표현하면 생성이기도 합니다. 원래 데이터를 복원한다는 것은 부호화된 데이터를 기반으로 새로운 데이터를 만들어내는 일이라고도 할 수 있습니다.
다시 번역 예로 돌아가보겠습니다. 한->영 번역은 한국어를 inter-lingua로 부호화한 다음, inter-lingua를 영어로 생성하는 작업입니다.
동영상이나 압축의 사례에서는 복원이라는 표현이 더 어울리고, 번역 사례에서는 생성이 더 잘 어울리는 표현입니다. 번역에서 복원이라고하면 한국어를 다시 한국어로 되돌리는 느낌이니까요.
동영상, 이미지, 압축의 예처럼 사실 부호화, 복원(생성)은 컴퓨터 공학에서 널리 쓰이는 구조입니다. 부호화, 복원(생성)을 쓰는 이유는 대표적으로 아래와 같습니다.
- 원본 데이터를 그대로 담기에는 너무 큰 경우: 동영상, 이미지, 음악파일 등이 이 경우에 해당합니다. 저장할 때 원본 그대로는 아니지만 작게 줄였다가(부호화), 필요할 때 최대한 원본대로 돌려보자(복원)는 아이디어입니다.
- 저장한(또는 전송 중인) 데이터를 남이 못 알아보게 하기 위해서: 암호화가 좋은 예입니다. 스파이가 본국에 첩보를 보낸다고 가정해보겠습니다. 일반적인 언어로 편지를 쓰면 누가 편지를 낚아챘을 때 바로 들통납니다. 그래서 스파이는 본국과 약속된 암호로 편지를 씁니다 (부호화). 그리고 편지를 받은 본국은 약속된 규칙에 따라 암호를 해독(복원)합니다.
- A -> B로 변환하는 법을 모를 때
마지막이 바로 우리의 관심사입니다. 압축과 암호화는 어떻게 압축하고 해제하는 하는지, 어떻게 암호화하고 복원하는지 압니다. 왜냐면 우리가 그 약속을 정했으니까요. 하지만 한->영 번역은 그 과정이 어떻게 되는지 우리는 모릅니다. 우리가 정하지 않았으니까요. 우리의 작전은 이렇습니다.
- 한국어가 영어로 어떻게 변환되는지 나는 모른다.
- 하지만 Sequence to Sequence 구조를 적용해보면 왠지 그럴 듯 할 것 같다.
- "원본 언어 -> 부호화 -> Inter-lingua -> 생성 -> 대상 언어" 라는 구조를 잡겠다.
- 그리고 나는 "원본 언어 -> 대상 언어" 쌍을 어마어마하게 모을거다.
- 그리고 이 데이터를 Deep Learning에게 주면 Deep Learning이 알아서 어떻게 부호화할지, 어떻게 다시 생성할지 배울것이다.
Deep Learning을 포함한 Machine Learning이 잘 하는 것이 뭔가요? 바로 A -> B 관계를 주었을 때 A -> B 사이의 관계를 배우는 것입니다. 딱! 우리가 하려는 일에 맞네요.
Encoder - Decoder 구조
지금까지 이야기한 아이디어를 좀 더 Deep Learning 스럽게 표현한 것이 Encoder - Decoder 구조입니다. Encoder - Decoder는 아래와 같은 구조를 갖습니다.
- Input -> Encoder -> Context -> Decoder -> Output
정확히 앞의 "원본 언어 -> 부호화 -> Inter-lingua -> 생성 -> 대상 언어"라는 구조와 일치합니다.
- Encoder : 부호화에 해당합니다. Encoder의 목적은 입력을 (우리는 이해못하지만) 어떤 새로운 형태로 변환하는 일입니다.
- Context : Inter-lingua에 해당합니다. 그런데 Context라는 단어가 워낙 여기저기에서 쓰이다보니 헷갈리는 합니다. 그래서 meaning vector, semantic representation 등등으로 불리기도 하는데 이 글에서는 계속 Context라고 부르겠습니다.
- Decoder : 생성에 해당합니다. Decoder의 목적은 Context를 다시 우리가 알 수 있는 자연어로 바꿔주는 일입니다.
그렇다면 Deep Learning에서 Encoder, Context, Decoder의 실체(?)는 무엇일까요? 행렬(Matrix)들입니다. Encoder는 입력 문장을 Context라는 행렬로 변환하는 행렬입니다. Decoder는 Context를 다시 대상 언어로 변환해주는 행렬입니다.
그런데 여기에는 한가지 중요한 연결고리가 빠져있습니다. Encoder, Decoder가 행렬이라면 Encoder의 입력도 행렬이어야하고, Decoder의 출력도 행렬일 것입니다. 그런데 실제로 입력과 출력은 모두 행렬이 아닌 자연어이고요. 그래서 추가로 자연어를 행렬로 표현해주는 방법과 행렬을 자연어로 표현해줄 방법이 필요합니다. 이를 위해서는 Embedding 이라는 새로운 개념이 필요합니다. Embedding 자체가 또 하나의 커다란 주제이기도 하고 이번 글에 필수적인 것은 아니라서 여기에서는 다루지 않으려고 합니다. 우선은 Embedding이라는 것을 통해 자연어를 행렬로 표현할 수 있다 정도로 약속(?)만 하겠습니다.
다시 Transformer
드디어 다시 Transformer입니다. Transformer는 이 Encoder - Decoder 를 기가 막히게 잘 하는 알고리즘입니다. Transformer가 뭔가 하고 찾아보신 분들은 십중팔구 아래 그림을 보셨을 것입니다.
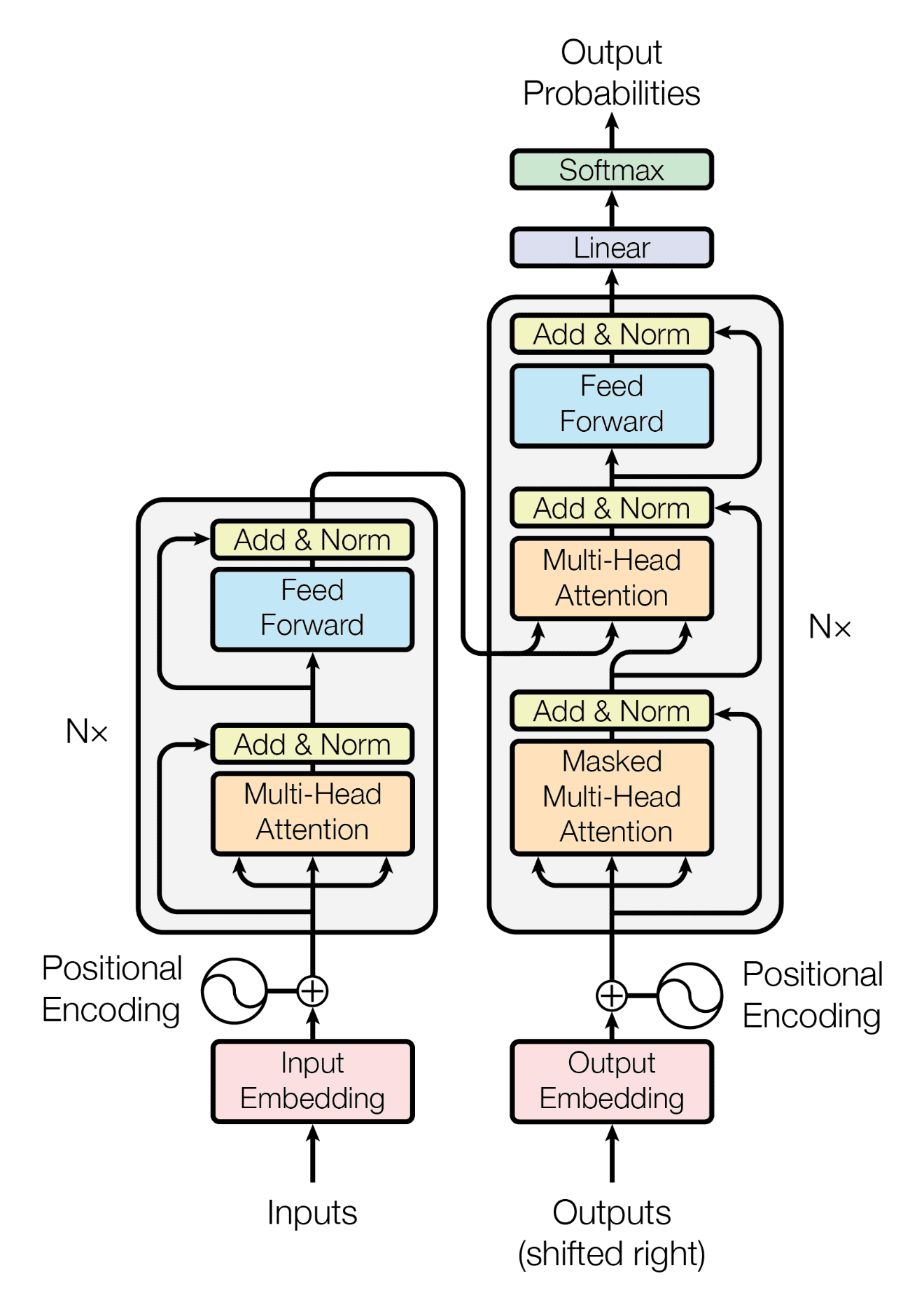
Transformer의 구조를 표현한 그림입니다. 왼쪽이 Encoder, 오른쪽이 Decoder입니다. Transformer도 근본은 Encoder-Decoder이기 때문에 작동하는 방식은 동일합니다.
"나는 어제 학교에 갔다."가 입력으로 들어오면 Encoder(왼쪽 회색 상자)를 쭉 타고 지나 Context(이 그림에는 표현되지 않았습니다)로 변환됩니다. 왼쪽 가장 위쪽의 Add & Norm에서 나오는 값이 Context입니다. 그리고 이 Context는 Decoder(오른쪽 회색 상자)의 입력으로 들어갑니다. Context가 Decoder의 Multi-Head Attention(뒤에 다룹니다)으로 들어가는 것을 볼 수 있습니다. 그리고 Decoder는 최종적으로 Output Probabilities라는 것을 만듭니다. Output Probabilities는 입력에 가장 적합한 문장이 무엇일지를 표현한 값입니다. Output Probabilities를 실제 자연어로 바꿔주는 부분은 이 그림에는 생략되있습니다.
이 부분을 간단히만 설명해보겠습니다. 영어에 단어가 10,000개가 있다고 가정해보겠습니다. 1번 단어는 a, 2번 단어는 apple, 8789번 단어는 went와 같이 번호를 붙입니다. Transformer의 입력으로 "갔다"가 들어왔다고 해보겠습니다. "갔다"는 Encoder, Decoder를 거쳐서 Output Probabilities가 나올 겁니다. 이 Output Probabilities를 뜯어보면 아래와 같습니다.
- 1 (a) : 0.00001
- 2 (apple) : 0.0004
- ....
- 8789 (went): 0.901
- ...
8789번 단어인 went가 답일 확률이 가장 높다는 것을 알 수 있고, 결과로 went를 선택합니다.
앞에서 말한 Encoder라고 표현한 것은 엄밀히는 Encoder Block입니다. 레고 블럭처럼 Encoder Block을 여러개 쌓을 수 있습니다. 1번 Encoder Block의 결과를 2번 Encoder Block의 입력으로 쓰고, 2번 Encoder Block의 결과를 3번 Encoder Block의 입력으로 쓰는 셈입니다. 마지막 Encoder Block의 결과가 Encoder의 최종 결과(Context)가 됩니다.
마찬가지로 Decoder도 엄밀히는 Decoder Block이고 Encoder와 마찬가지고 여러개를 쌓을 수 있습니다.
이렇게 Encoder Block과 Decoder Block을 여러개 쌓으면 어떤 점이 좋을까요? 기본적으로 Deep Learning 모델을 키우는 것과 같은 효과가 있습니다. 모델이 커질수록 모델의 표현력이 좋아지고 성능이 좋아진다는 원리에 따른 것이죠.
하지만 데이터가 부족한데 모델만 키워봤자 효과는 없습니다. 오히려 성능이 더 나쁘지기도 하죠. 또다른 단점은 모델이 커질수록 훈련시키고 서비스하기 위한 하드웨어 요구사항이 높아진다는 점입니다.
그래서 Transformer와 Language Model은 어떤 관계?
좀 더 자세한 이야기를 하기 전에 Transformer와 Language Model의 관계에 대해서 짚어보겠습니다. 이야기가 길어져서 놓칠 수 있지만 우리는 (Large) Language Model이 가능하게 된 요인 중 하나로 Transformer 이야기를 하고 있으니까요 :)
다시 떠올려보면 Language Model이 하는 일은 "주어진 텍스트 바로 뒤에 올 단어를 예측" 하는 것입니다. "길가에 꽃이 흐드러지게" -> 다음에 "때렸다."가 아니고 "피었다."라고 예측하는 일입니다.
그럼 Transformer가 다음 단어 예측을 잘 하느냐? 네, 그것도 아주 기가 막히게 잘합니다. Transformer를 사용해 다음 단어를 예측하게 하는 것은 Transformer와 Language Model을 이해하는데 매우 중요한 개념입니다.
다시 "나는 어제 학교에 갔다." 예제로 돌아가보겠습니다. 이 문장이 Encoder를 거치고 나면 Context라는 행렬로 변환(부호화)됩니다. 즉, Context 행렬은 "나는 어제 학교에 갔다."라는 문장을 숫자 형태로 가지고 있습니다. Context에 담긴 정보가 무엇이냐는 또 엄청난 연구 주제입니다. Context에 담긴 것이 어휘냐, 문법이냐, 아니면 그 이상의 의미적인 것이냐 등등. 하지만 이 글에서는 Context에 우리한테 필요한 정보가 다 들어있다라는 사실이면 충분합니다.
이제 Decoder가 이 Context를 입력으로 받겠죠? 여기에서 Transformer 구조 그림을 다시 한번 자세히 봐야합니다.
그림의 Decoder (오른쪽 회색 상자)를 보시면 Encoder에서 나오는 화살표도 있지만 아래 쪽에 Outputs 이라고 표시된 또다른 입력도 있습니다. 사실, Transformer Decoder의 입력은 두가지 입니다.
- Encoder가 만든 Context
- Outputs
입력인데 이름은 Outputs 이라니 이름이 상당히 헷갈립니다. 하지만 여기에는 매우 중요한 의미가 있습니다. 이 Outputs 이라는 것은 도대체 어디에서 왔을까요? 바로 Decoder의 Output입니다. Output Probabilities라고 표현된 부분입니다. 앞에 설명한대로 Output Probabilities = Decoder가 결정한 다음 단어(정확히는 토큰이지만 현재 논의에서 중요한 부분은 아닙니다)라고 생각해도 좋습니다. 다르게 이야기해보면, Decode의 결과가 다시 Decoder의 입력으로 들어간다는 뜻입니다. 더 헷갈리는데요. 예를 들어보겠습니다.
"나는 어제 학교에 갔다."를 영어로 변역하고 싶다고 해보죠.
1, Encoder가 "나는 어제 학교에 갔다."를 Context로 변환합니다.
2. Decoder는 두 가지 입력 (Context와 Outputs)이 필요합니다.
3. 아직 Decoder의 Output은 없기 때문에 Outputs은 빈 문장(정확히는 )을 Outputs으로 사용합니다.
4. Decoder는 Context와 빈 문장을 조합해서 한 단어를 예측합니다. 예측한 단어는 I라고 해보겠습니다.
5. 4단계를 반복합니다. Context는 변하지 않습니다. 하지만 이제 Decoder의 Output이 있습니다. 바로 I죠. 이제 Context와 "I"를 사용해서 다음 단어를 예측합니다. 예측한 단어는 went라고 해보겠습니다.
6. 4단계를 또 반복합니다. 이번에는 Output이 "I went"가 됐습니다. Context와 "I went"를 가지고 다음 단어를 예측합니다. 예측한 단어는 to라고 해보겠습니다.
7. 이 과정을 계속 반복하다가 (to, the, school, yesterday. 가 나오겠죠) 라는 특별한 단어가 예측되면 멈춥니다.
8. 결국 Decoder가 예측(생성)한 단어들을 합치면 "I went to the school yesterday."가 됩니다.
중요한 두가지 개념이 등장했습니다.
- Decoder는 한번에 하나의 단어(토큰)를 예측합니다. 문장을 한번에 예측하지 않습니다. ChatGPT를 써보시면 마치 타이핑하듯이 결과가 나오는 것을 볼 수 있는데 바로 이 때문입니다.
- Decoder가 예측(생성)한 결과가 다시 Decoder의 입력으로 들어갑니다. 이런 특성을 auto-regressive라고 합니다.
Language Model이 하는 일은 주어진 텍스트에 이어질 다음 단어를 예측하는 일이라고 했습니다. 위의 첫번째 개념이 바로 여기에 해당합니다.
하지만 의문이 생깁니다. 우리가 하고 싶은 것은 번역이 아니라 다음 단어를 예측하는 일입니다. "길가에 꽃이 흐드러지게" 다음에 "피었다."를 예측하고 싶습니다. 이 일을 하기 위해서는 Transformer 구조를 살짝 바꿔야합니다.
Encoder only, Decoder only
Encoder - Decoder 구조를 가진 Transformer가 강력하기는 하지만 모두가 이 구조를 원하는 것은 아닙니다. 예를 들어 앞에 설명한 Language Model 태스크가 그렇습니다. 그래서 사람들은 Transformer를 살짝 살짝 변형하기 시작합니다. Encoder만 쓰면 어떻게 되지? Decoder만 쓰면 어떻게 되지? 하는 생각들을 하게됩니다.
Encoder only
가장 대표적인 Encoder only 구조인 BERT의 구조도입니다. 그림을 이해할 필요는 없습니다 :) 우리는 BERT가 Transformer 에서 Encoder 부분만 사용한다는 것을 알면 됩니다.
언제 Encoder만 필요할까요? Context를 만드는데까지만 관심있고 생성(Decoder)은 관심이 없는 경우입니다. 이런 경우가 언제일까요? 대부분의 Classification 태스크가 여기에 해당합니다. 기본적으로 Classification은 자연어를 행렬 형태(Embedding)로 바꾸고, 이 행렬(Embedding)에 대해 Classification을 수행하는 단계를 거칩니다. 자연어를 행렬 형태로 변환하는 작업을 Embedding한다고 합니다. 어떤 때는 문장 전체를 Embedding해야하고(리뷰가 긍정인지 부정인지), 어떤 때는 각 단어를 Embedding해야합니다(문장에서 사람이름만 찾기).
Classification은 결국 Embedding을 대상으로 하기 때문에 얼마나 자연어를 잘 Embedding 하느냐가 Classification 성능에 직결됩니다. 그동안 수많은 Embedding 기법들이 나온 이유이기도 합니다. 현재 Embedding 계의 왕좌에는 BERT가 앉아있습니다. BERT는 문장을 양방향으로 본다거나, 문장 전체를 보기 때문에 문장 전체의 의미를 더 잘 표현한다거나 하는 장점들이 있습니다. 그리고 무엇보다 BERT를 쓰면 Classification의 성능이 좋아집니다!
하지만 BERT는 Language Model일까요? BERT는 Decoder가 없기 때문에 다음 단어를 예측할 수 없습니다. 그렇다면 주어진 문장이 자연스러운지 평가(점수) 할 수 있을까요? 기본적으로는 안되지만 BERT를 사용해서 문장의 점수를 평가하는 기법들이 있습니다.
따라서 BERT를 엄밀히는 전통적인 Language Model이라고 부르기는 어렵습니다. 우리가 BERT를 Language Model이라고 부를 때는 전통적인 Language Model이라는 개념보다는 확장된 "언어를 모사한 모델"이라는 관점인 경우가 많습니다.
Decoder only
가장 대표적인 Decoder only 구조인 GPT의 구조도입니다. 역시 그럼을 이해하실 필요는 없습니다 ;)
GPT는 GPT-2, GPT-3, ChatGPT, GPT-4로 발전하면서 요즘 가장 뜨거운 모델이기도 합니다. Decoder만 쓰게되면 어떤 효과가 생길까요?
먼저 Encoder가 필요했던 이유를 생각해봅시다. Encoder는 변환하려고하는 입력 문장을 숫자(행렬)로 표한하기 위해서 필요했습니다. 그리고 이 행렬을 기반으로 Decoder가 다른 문장을 생성했습니다. 하지만 이런 전체적인 문장->문장 변환에 관심이 없다면 어떨까요? 단지 Language Model이 하는 것처럼 주어진 텍스트 다음에 올 단어를 예측하는 것에만 관심이 있다면?
그렇다면 Encoder의 결과(Context)는 필요없습니다. Context는 변화할 원본 문장을 표현한 것이니까요.
앞에 Transformer Decoder가 작동하는 방식에서 설명했지만 Decoder의 입력은 두가지입니다.
- Context
- Outputs
Context를 쓰지 않고 Outputs만 입력으로 쓰면 어떻게 될까요? 예를 들어 Context는 쓰지 않고 "길가에 꽃이 흐드러지게"만 Outputs으로 줍니다. 그럼 Decoder는 "피었다."를 예측할 겁니다. Encoder - Decoder 방식에서 Decoder가 했던 일이 Context와 Outputs 정보를 조합해서 다음 단어를 예측하는 일이었으니까요.
어디에서 본 것 같지 않으신가요? 바로 Language Model이 하는 다음 단어 예측입니다.
즉, Transformer의 Decoder 만을 사용하면 전통적인 Language Model을 만들 수 있게 됩니다. 그리고 auto-regressive 방식을 사용하면 계속해서 긴 글을 만들 수도 있습니다.
GPT가 가장 유명한 Decoder only 모델이지만 그 외에 최근에 화제가 되는 생성형 언어 모델들은 전부 같은 Decoder only 방식입니다. LaMDA, PaLM, LLaMA, Claude 등등이 여기에 해당합니다.
Encoder and Decoder
BERT나 GPT 보다 대중적인 영향력은 덜 한 것 같지만 기존의 Transformer의 구조를 살려서 Encoder와 Decoder를 모두 쓰는 방식도 있습니다. T5, BART 같은 모델들이 예입니다.
Encoder only vs Decoder only
두 가지 중 먼저 완성도가 올라오고 널리 쓰이기 시작한 것은 BERT로 대표되는 Encoder only 방식이었습니다. 워낙 기존 NLP 태스크가 Classification 위주였기도 하고, GPT로 대표되는 Decoder only 방식이 만들어내는 텍스트가 흔히 말하는 아무말 대잔치에 머물렀기 때문입니다.
하지만 잠재력에서는 두 방식 사이에 커다란 차이가 있습니다. Encoder 방식은 결국 생성은 할 수 없다는 한계가 있습니다. 하지만 Decoder 방식은 생성을 할 수 있기 때문에 무한한 가능성이 열려 있습니다. 보통 Classification 문제라고 생각했던 것도 얼마든지 생성 방식으로 바꿀 수 있습니다. 앞의 Sequence to Sequence 설명에서 예를 들었다 긍정, 부정 판단과 문장에서 사람이름 찾기가 그 예입니다.
그럼 어떻게 Decoder only 모델이 한계를 극복하고 대세 LLM이 되었을까요? 이 이야기는 나중에 다시 하기로 하고, 지금은 Transformer의 아주 중요한 개념을 이야기해보려고 합니다.
Encoder - Decoder 구조의 유구한 역사
Transformer가 Encoder - Decoder 방식을 위한 최초의 알고리즘은 아닙니다. Encoder - Decoder 방식은 아주 오래된 아이디어이고 Machine Learning 에서도 초반부터 사용한 방식입니다.
Transformer 가 등장하기 전에 Encoder - Decoder 방식을 구현하기 위해 가장 널리 쓰인 알고리즘은 RNN(그리고 비슷한 계열인 LSTM, GRU 등)입니다. 사실 2017년 Transformer가 등장하기 전에는 RNN이 자연어처리의 표준과 같았습니다. 그 자리를 지금 Transformer가 대체한 것이고요.
도대체 Transformer의 어떤 점이 RNN을 몰아내고 왕좌를 차지하게 만들었을까요? 여러가지 기술적인 요인이 있지만 가장 많이 꼽는 것은 바로 Self-Attention입니다.
Transformer는 왜 이렇게 잘 작동할까? Self-Attention
Transformer의 기술적인 내용은 매우 복잡하지만 가장 중요한 개념은 Encoder - Decoder와 Self-Attention입니다. Self-Attention을 이해하기 위해서는 먼저 Attention을 이해해야합니다.
Attention
Attention은 RNN 기반의 Sequence to Sequence에서 사용된 주요 개념입니다. 다시 Sequence to Sequence 구조를 꺼내보겠습니다.
- Input -> Encoder -> Context -> Decoder -> Output
Decoder는 앞에 설명드린 Auto-regressive 방식으로 한 단어씩 Output을 만들어갑니다. 하지만 Context는 Encoder가 만든 그대로 변하지 않고 그대로입니다.
"나는 어제 학교에 갔습니다." 예시를 다시 보겠습니다. Encoding 과정을 끝내고 이 문장에 대한 Context가 계산됐습니다. 그리고 Decoder가 첫번째 단어인 I를 예측했습니다. (결국은 I went to the school yesterday.를 예측해야합니다.) 이제 Auto-regressive 방식대로 I를 새로운 입력으로하고 Context와 함께 참고해서 다음 단어를 예측하려고 합니다. 이전과 달라진 것은 입력에 I가 추가됐다는 것 뿐입니다. 잘 될 수도 있지만 예상보다 예측이 잘 되지는 않습니다. 이때 똑똑한 연구자들이 아이디어을 생각해냅니다.
- 현재 단어를 예측할 때 Context의 어느 부분을 더 집중해서 봐야할지 알 수 있으면 좋지 않을까? 예를 들어 I 다음을 예측할때, 갔습니다를 고려하면 go를 고를 수 있을 것 같다. 어제를 봐야한다는 것을 알면 과거형인 went를 고를 수 있을텐데. 이때 학교에는 별로 중요한 정보는 아니고.
기가 막힌 아이디어가 아닌가요? 이렇게 Decoder의 각 단계에서 Context의 어느 부분을 더 집중해서 보고, 어느 부분은 덜 집중해야하는지 알려주는 정보를 Attention이라고 합니다.
Self-Attention
Attention은 번역 대상 문장이 입력 문장의 어느 부분을 집중해야하는지 알려주는 정보입니다. Context는 결국 입력 문장의 다른 형태이니까요. Transformer는 비슷하지만 살짝 다른 Self-Attention이라는 개념을 사용합니다. 문장 내에서 집중해야할 것과 덜 집중해야할 것을 나타낸다는 점에서 Attention이지만 그 대상이 다른 문장이 아니라 자기 자신이라는 점에서 Self입니다. 예시를 보죠.

Self-Attention을 찾다보면 많이 나오는 그림입니다. it은 의미상 animal과 관련이 가장 높습니다.
단어와 단어 사아의 관련성을 알면 왜 Language Model에 도움이 될까요? Language Model이 하는 일은 다음 단어를 예측하는 일입니다. 다음 단어를 예측하기 위해서는 앞선 단어들을 고려해야겠죠. 앞선 단어들 중에 어떤 단어를 고려해야할까요? 직전 단어? 모두 똑같이? Self-Attention은 이 질문에 답을 줍니다.
"길가에 꽃이 흐드러지게" 다음 단어("피었다.")를 예측하려면 아마도 꽃이라는 단어가 가장 중요할 겁니다. "길가에 꽃이 흐드러지게 피었다."의 Self-Attention 계산을 해보면 꽃이와 피었다 사이에 높은 관련성이 있다고 나올 겁니다. 흐드러지게도 어느 정도 높은 점수가 나오겠네요.
다시 앞의 영어 예시로 돌아가보면 it이 animal과 관련이 있는 것은 직관적인데 it과 다른 단어의 관계는 어떤가요? 보기에 따라 it이 tired 한 것이기 때문에 두 단어 사이에도 관련성이 있어보입니다. it과 animal 이 서로를 가르키는 문법적인 관계라면, it과 tired는 속성을 나타내는 관계일 수 있습니다.
이런 관계의 복합성(?)을 표현하기 위해 등장한 개념이 Multi-head Self-Attention입니다.
Multi-head Self-Attention
간단히 하려고했던 이야기가 점점 헤어날 수 없는 지경으로 빠져들고 있습니다. 예를 먼저 보고 가시죠.

주황색으로 표현된 Self-Attention에서는 it과 animal 사이의 관련이 높지만, 녹색으로 표현된 Self-Attention에서는 it과 tired의 관련이 높습니다.
Self-Attention은 단어간의 관계를 수치(점수)로 표현하기에 아주 좋은 도구입니다. 하지만 언어에 담긴 관계는 여러가지 관점이 있을 수 있습니다. 문법적인 관계, 의미적인 관계, 비슷한 어휘 등등을 생각해볼 수 있습니다. 그리고 연구자들이 발견한 것은 Self-Attention 하나로 이 모든 언어학적 관계를 표현하기 어렵다는 점입니다. 그렇다면 어떻게 할까요? 다다익선이라고 Self-Attention을 여러개 만듭니다. Self-Attention이 여러개 있다고 해서 Multi-head Self-Attention입니다. 그리고 각각의 Self-Attention은 문장의 다른 부분을 관찰하도록 만듭니다.
여기에서 다른 부분은 단어를 의미하는 것이 아닙니다. 문장이 Embedding을 거치고 나면 숫자(행렬)로 표현되는데, 이 행렬을 여러 부분으로 쪼개고 각 Self-Attention이 다른 조각들을 관찰하게 만듭니다. Embedding이 문장을 행렬로 표현한 것이고, 행렬의 부분 부분은 문장의 여러 요소(문법, 의미, 형태 등)를 표현하지 않을까?라는 아이디어입니다.
내용이 다소 복잡한데요. 중요한 것은 "Self-Attention을 여러개 만들어서 각 Self-Attention이 문장의 여러 요소 (문법, 의미, 형태 등등)를 모두 고려하도록 했다"는 사실입니다.
175B? 540B 파라미터 수는 무엇인가?
LLM의 크기를 이야기할 때 보통 175B(GPT-3) 크기이니, 540B(PaLM) 크기이니 같은 이야기를 많이합니다. 이 숫자들이 의미하는 것은 무엇일까요? 바로 모델을 구성하는 Transformer의 Neural Network 파라미터 수입니다. 파라미터 수가 많다는 것은 Neural Network가 복잡하다는 뜻이고, Neural Network가 복잡하다는 것은 그만큼 모델이 강력하다는 뜻입니다. 그래서 파라미터수가 많다 -> 성능 좋은 모델이라는 통념이 생겨납니다.
하지만 이것은 전체 그림 중 일부일 뿐입니다. LLM 뿐 아니라 Machine Learning에서 모델의 성능을 결정하는 것은 모델의 크기 외에도 많은 요소가 존재합니다. 얼마나 많은 데이터를 썼는지, 얼마나 양질의 데이터였는지, 모델의 하이퍼 파라미터들은 얼마나 잘 튜닝했는지, 얼마나 오래 충분히 훈련시켰는지 등 고려해야할 요소가 많습니다.
그럼에도 불구하고 LLM을 이야기할 때 175B, 540B 처럼 파라미터수를 주로 이야기하는 이유는 무엇일까요? 이 숫자들이 이해하기 쉽기 때문이라고 생각합니다. A LLM이 좋아, B LLM이 좋아?라는 질문을 받았을 때 파라미터 수, 데이터 양, 질, 훈련시간 등등을 모두 따져서 설명하는 것은 어려운 일입니다. 그리고 답을 듣는 입장에서도 어려운 일입니다. 하지만 단순화 시켜서 "A LLM은 70B 급이고 B LLM은 200B 급입니다. B LLM이 더 좋아요."라고 한다면 이해하기 쉽고 모두가 행복합니다. 정확한 답이 아니라는 사실만 뺀다면 말이죠.
LLM(그리고 여타 Deep Learning 모델)의 품질을 이야기할 때 파라미터 수만 강조하는 사람이 있다면 조심하세요. 잘 모르는 사람이거나 장사꾼일 가능성이 높습니다.
Transformer 요약
아주 길었던 Transformer 이야기를 요약해보겠습니다.
- Transformer는 Sequence to Sequence 방식을 위해 만들어진 알고리즘이다.
- 특히 Sequence to Sequence 에 가장 많이 사용되는 Encoder - Decoder 방식을 따른다.
- Transformer 기반 모델들에는 Encoder only (BERT), Decoder only (GPT), Encoder and Decoder (T5) 방식이 있다.
- 언어를 생성하기 위해서는 Decoder가 필요하다.
- Transformer의 핵심 개념 중 하나는 Self-Attention이다.
- 여러 관점에서 Self-Attention을 보기 위해서 Multi-head Self-Attention을 사용한다.
컴퓨팅 파워
이제 마지막 세번째 요소인 컴퓨팅 파워 이야기를 해보겠습니다. 컴퓨팅 파워 이야기는 간단합니다. 그동안 엄청나게 강력한(빠른) 컴퓨터들이 개발됐습니다. Deep Learning 시대를 열었던 것 중 하나가 GPU를 사용한 빠른 계산이었습니다. 완전히 새로운 패러다임이 생기지는 않았습니다. GPU(혹시 TPU)가 훨씬 더 빨라졌고, 여러 GPU를 동시에 사용하기 위한 병렬처리 기법들이 발전했습니다.
여전히 GPU 의 최강자는 Nvidia입니다. 여기에 박차를 가하기 위해 Nvidia는 훈련 소프트웨어 개발에도 많은 노력을 기울이고 있습니다. 좋은 소프트웨어가 있어야 사람들이 Nvidia GPU도 많이 살테니까요.
클라우드 인프라의 발전도 한 몫하고 있습니다. 저 비싼 GPU 장비들을 직접 산다면 비용도 문제지만 이후 처리가 더 곤란합니다. 사는 순간부터 중고고 감가삼각이 시작되니까요. 아마존, MS 등이 Deep Learning 을 위한 클라우드 인프라를 빠르게 발전시키고 있고, 이 점이 LLM 발전에 큰 기여를 하고 있습니다.
'Deep Learning' 카테고리의 다른 글
| Cross Entropy 이야기 (0) | 2023.05.21 |
|---|---|
| LLM : In-Context Learning, 남은 이야기들 (13) | 2023.04.12 |
| LLM : Foundation Model (2) | 2023.04.12 |
| 머신 러닝 + 자연어 처리 (1) | 2022.03.26 |
| Transformer로 한국어 품사 태거 만들기 (0) | 2021.06.13 |